The $100 Movie: How AI is Transforming the Film Industry

AI for film production is improving rapidly — certainly a lot faster than James Cameron making an Avatar sequel.
If you watched Indiana Jones: Dial of Destiny or The Irishman recently, you saw one of the more presently viable use cases for AI in film — de-aging your dad’s favorite actors like Harrison Ford and Robert De Niro. And though these breakthroughs in AI might have taken a job away from a young De Niro lookalike, the millions of dollars spent on VFX teams to create this effect shows that maybe some of the AI replacement fears in Hollywood have not quite come true yet. Though de-aging and face-swapping in contemporary films is attributed to AI, if we dig a little deeper most of it takes place not at sleek new Silicon Valley tech companies, but at ILM, a company started by George Lucas that employees hundreds of creatives. The process, needless to say, remains high touch.
But that might not be true for long.
Then RunwayML released Gen-2, a multimodal AI system can generate videos from text, images, and video clips, and suddenly we saw a deluge of AI-generated video clips. The best of these look like they would take an experienced animator hours or days to recreate. HeyGen released a video translation and lip reanimation tool that produced shockingly natural outputs. And just recently Stability AI open-sourced their own video model, on top of which we can expect a huge number of applications to be built in the coming months, the same way their image generation model created an explosion of new fine-tuned image generation software.
We have seen several times over how new creative tools empower new groups of people to branch out from consumer to creator, which then serves as the engine for new media platforms. We saw this with YouTube and the Adobe creative suite. Suddenly this platform could be populated with high quality short films produced by people in their own homes. But most people did not become YouTubers nor did they learn how to use Premier. I think the adoption of these tools relative to the consumer base is reflective of how difficult they are to use. Even in it’s mature state, there are a limited number of successful creators on YouTube, and content production tends to still be quite expensive. Newer UGC (user generated content) platforms like TikTok have created an ecosystem where a much larger number of creators can be much, much larger. This seems in line with the relatively lower barrier of entry. As new AI tools make it possible to produce high quality content more cheaply and easily, it is likely that it will empower an even larger number of creators to bring their thoughts and ideas to life in film.
There are a huge number of places where AI will touch the film industry, from screenwriting to production financing, to casting, and everything else that happens off screen. For this post, I want to explore specifically how AI-powered creative tools can empower indie film makers, meaning many of the production tools are out of scope. For this domain, I see five areas where startups are using AI to make film production easier, ranked from most currently functional to most in development: audio, animation, editing, and video generation.
Audio
Audio is an expensive and complicated part of making a film. There are two distinct areas of audio that are both quite costly — scoring and voice acting. For an indie film, both score and voice actors come with price tags in the thousands. Using traditional tooling, doing either without hiring a profession is difficult and time consuming. I’ll skip some of the AI scoring solutions, since AI for music generation has been well-covered elsewhere. For voice generation, we have text to speech models. Though text to speech has been around for over 50 years, it is only with recent advances in generative AI that the “robot voice” problem has been solved. Startups like ElevenLabs and Neosapience have built extremely realistic text to speech models that are nearly indistinguishable from human voice (the giveaway is mainly in occasionally unnatural inflection). Both can emulate existing voices very well from only a few minutes of sample. ElevenLabs is focused mainly on selling into the application layer, whereas Neosapience has focused on building tooling for the film industry. Although the highest quality text to speech remains prohibitively expensive for conversational apps, the cost of inference for the 1-2 hours of speech need for a film is minimal. Through ElevenLabs this can currently be done for free.
(ElevenLabs speaking my favorite language, Finnish)
An important use of voice acting is not just for creating original content, but also for dubbing content in foreign languages. Dubbing historically has been an expensive process, requiring translators, voice actors, and audio engineers to produce and embed dialogue in another language. And even in the best case scenario, in a live action film dubbed with traditional methods the speech does not match the actors mouths. Though in theory VFX artists could reanimate actors’ mouths to match the new language, it is never done because it is so high cost and many viewers are already somewhat acclimated to watching mismatched audio. Companies like Deepdub and HeyGen offer a solution to this. Both are end-to-end tools for “immersive dubbing”, meaning you can upload a video, and the audio will automatically be translated to the target language using the original voice, and the mouths in video will be reanimated to match the audio. The demos are compelling, but trying it on a video of yourself is truly strange, like seeing yourself learn a new language fluently in a few minutes. For creators just putting content on platforms like YouTube or Vimeo, dubbing is probably an unrealistic expense. These tools may massively increase distribution potential. (There is another interesting part of film audio called foley, but I’ll cover that in a later post).
Animation
Before getting into full-blown AI-generated animations, which is still not quite ready for long form video, it’s worth looking at how AI is being leveraged already in modern animators’ workflow. There are two interesting things to look at: background generation and motion capture. In most animation studios, background design is usually handled by a separate team, who spends a lot of time designing and drawing the background scene for every shot in the film. These are typically static art on top of which the moving characters and objects are superimposed. For indie animators, creating background art for every scene is an extremely time-consuming process, which can enormously sped up with image generation. Midjourney, Dall-E, and Stability already produce results that are indistinguishable from big budget animated films.

(Whether you are an artist or not, it’s easy to imagine how much additional time the background art here would take to produce without AI. This example in particular was made with Dall-E.)
The other interesting area is in motion capture. For 3D animation, it is often cheaper and produces much higher results to animate characters based on the physical movements of a human in a mo-cap studio, rather than animating the wireframe by hand. This is standard practice now for most major animation studios, but the technology remains very expensive. A high quality studio can cost over $100k to set up, and rentals usually go for around a thousand bucks an hour. Recent advances in computer allow us to generate these same wireframes from just a single video, shot on a phone. The results of companies like Move and Wonder Dynamics are astounding. Move is more oriented towards animated content and gaming, while Wonder Dynamics is focused on CGI for live action. Both highlight how a character model can be animated in very complex ways with minimal effort.
Tool Editing
I think it’s worth drawing a distinction between “tool editors” and “prompt editors”. The former is the traditional digital workstation like iMove or After Effects. The software gives you an enormous arsenal of virtualized tools which allow you to change video footage by clicking around in the frames. Machine learning models have already made these tools infinitely more powerful. Things like rotoscoping, object deletion, and match cutting have existed in these tool editors well before they were integrated with ML techniques, but using them required extremely skilled artists to spend hundreds of hours working at a very granular level — often editing frame-by-frame. Traditional computer vision methods have made these tools much more effective, for example finding good candidate shots for transitions at Netflix, or isolating actors in After Effects. Similarly, generative AI can make many of these tools even more effective. Updates to After Effects use generative models for denoising, text-based video editing (i.e. cutting a video just by editing the transcript), and color correction. Although these improvements save sophisticated users a great deal of time, there is still a significant learning curve to using these tools effectively. AI-native editing tool startups like RunwayML have simplified this process while still delivering professional-level results. They recently gained some attention after being used to create profession-level visuals in indie smash hit “Everything Everywhere All At Once.” Most of Runway’s current offering, like Adobe is tool-based. This is contrasted with a new modality of video editor, “prompt editors”, where users upload a video and describe in natural language the way they would like to change it.
(The powerful, but incredibly complex Adobe AfterEffects interface)
Video Generation/Prompt Editing
There is a spectrum from simple prompt editing to full-blown video generation that reflects the amount of visual input required from the user to turn written video description into satisfactory results. The simplest prompt editing looks something like adding motion or camera movement to a still image. At the other end of the spectrum is aesthetic, photorealistic, long form, multi-shot video generation. The former is already here, although so far has been limited to producing clips a few seconds in length and for the most part the results are still not excellent. The latter will likely not arrive for some time. It’s worth playing with tools like Genmo, Runway, Pika, and Stability to see what the future holds for video generation, but it’s hard to imagine producing a film this way any time soon.
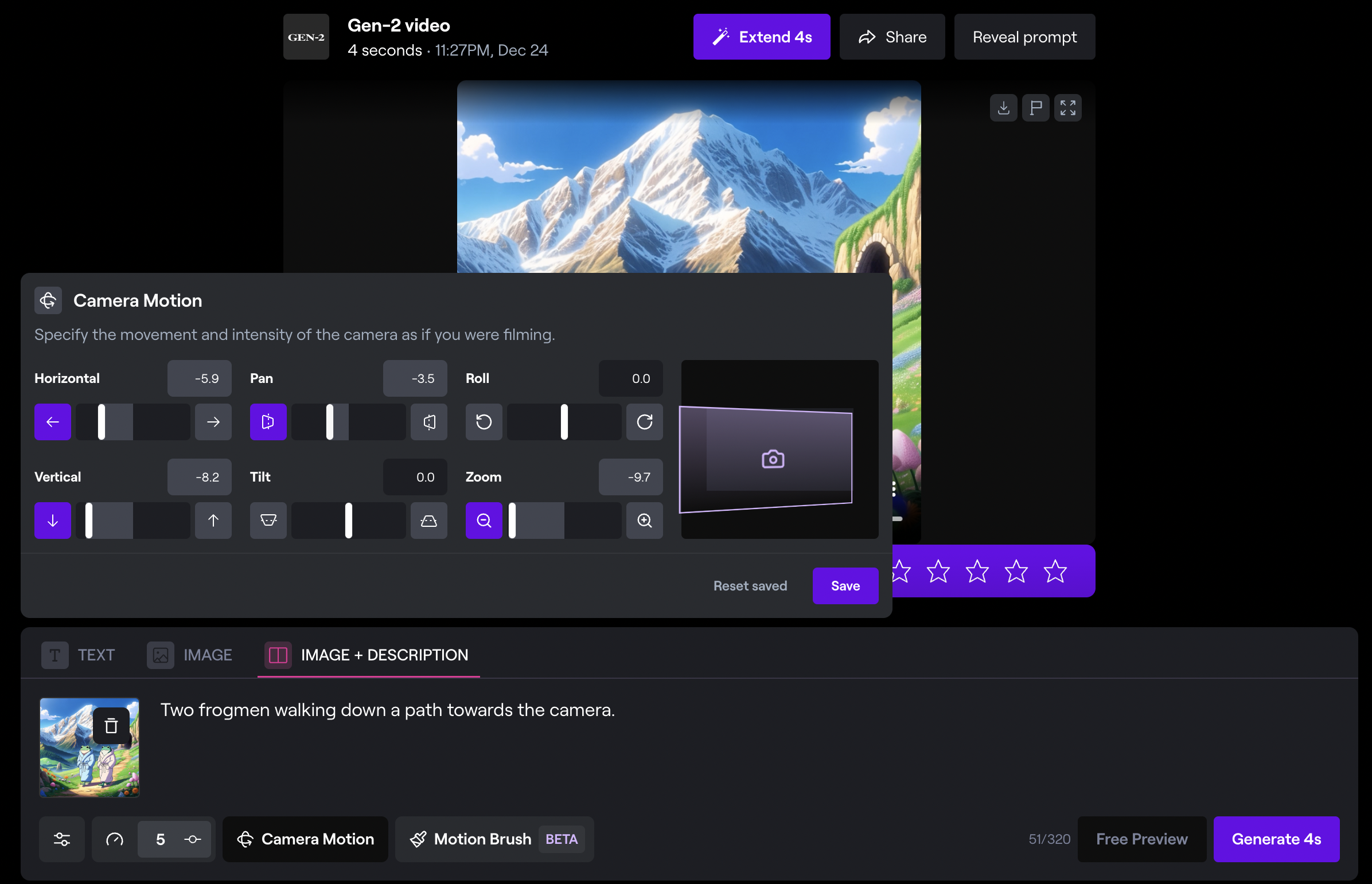
(Animating a video in RunwayML)
The Future
There are two key components to thinking about how AI will change the film industry: production and consumption. I’ve mostly covered production in this post. New technologies enable creators to make content faster, more cheaply, and with less specialized knowledge and equipment. It is already starting to level the playing field, and soon enough creators with no domain expertise will be able to make films that, at least aesthetically, match films being made today. That being said, I believe people will always find clever ways to produce box office hits with nine figure budgets. One of the ways this might happen is with new consumption modalities for film. Imagine how watching a film could become a two-way street. There are ways to make films more interactive now (think choose-your-own-adventure films, or even heavily narrative-driven video games), but they are clunky and very expensive to make. They are also generally quite limited to a predetermined set of experiences. What would it look for films to have rich interactive experiences, where the viewer is deeply embedded both within the narrative and in the process of creating it. It’s hard to know exactly what this could look like and what elements of this will be sticky, but I find it the most exciting frontier of filmmaking we are likely to pass in the next decade.